As the Preliminary Stage has already been explained above, please refer to the Concrete Example without Formulas Stage 1 section (beginning on page 3) for the basic information regarding these elements.In this section, more details and technical considerations are provided.
Agreeing on the Translation Specifications
It is worth repeating that evaluators must review the agreed-on specifications and have them accessible during evaluation for reference. For more information on translation specifications, please see the Further Readings section.
Verifying (or Selecting/Creating) a Metric
To avoid overwhelming evaluators, the number of error types included in the metric should be kept at a manageable amount. For most translation projects, this number is around 12-15 error types, although the number may be fewer or greater depending on the needs and specifications of the project. Again, note that when creating a metric, it is not necessary to include all dimensions.
The complete MQM Core Typology is available on the MQM website (see Further Reading and Links), which has descriptions and examples for each error type.
Error Severity Levels & Severity Penalty Multipliers
When annotating an error, evaluators typically assign it a severity level. Evaluators should refer to the translation specifications and consider possible end-user outcomes when deciding error severity levels. In some approaches to TQE, the severity level is implied by the error type.
In this example, severity levels are connected with severity penalty multipliers, which are values that represent the weight of errors when used to calculate the Absolute Penalty Total (APT) and the Overall Quality Score (OQS). Although different severity level multipliers can be established for any project, MQM uses a setting that is common throughout the translation community. The severity penalty multipliers used in the Elections Text example are Neutral = 0, Minor = 1, Major = 5, Critical = 25. Each severity level is described below in this section.
The “Neutral” severity level is used when a portion of the target text is highlighted for some reason, but does not contribute any points to the APT. Neutral errors can identify preferences or areas that may require additional revision, but that do not necessarily reflect errors or pose a risk to target-text users. Similarly, the neutral severity level can mark repeated errors (additional instances of exactly the same error, e.g. a spelling error of the same word used throughout the text).
Minor, Major, and Critical errors do contribute to the Absolute Penalty Total. Obviously, any non-neutral error that is detected would usually be corrected before delivery and use. On deciding whether to mark an error as Minor, Major, or Critical, the evaluators should ask themselves: “What if this error was not detected until after publication (or some other point that is not convenient to make corrections)?” “What would be the impact on the usability of the text for its intended audience and specified purpose?
“Minor” errors are errors that would not impact usability or understandability of the content. If the typical reader/user is able to correct the error reliably and it does not impact the usability of the content, it should be classified as minor.
“Major” errors are errors that would impact usability or understandability of the content but which would not render it unusable. For example, a misspelled word that may require extra effort for the reader to understand the intended meaning but does not make it impossible to comprehend should be labeled as a major error. Additionally, if an error cannot be reliably corrected by the reader/user (e.g., the intended meaning is not clear) but it does not render the content unfit for purpose, it should be categorized as major.
The “Critical” severity level is for errors that would render a text unusable, which is determined by considering the intended audience and specified purpose. Critical errors would usually result in damage to people, equipment, or an organization’s reputation if not corrected before use. In evaluating the quality of a translation, one single critical error will result in the text receiving an automatic “fail” rating. Sometimes, critical errors that are not detected and corrected in time will have to be corrected after publication, often at great cost. This is one reason that TQE before delivery is so important.
Assigning or Selecting the Threshold Value
For any given project, exact value Threshold Values (TVs) are determined by translation quality stakeholders by weighing specifications against a given evaluation scale. Another factor in determining a Threshold Value is the translation grade that was requested. For more information about translation grades, see the Further Reading and Links section below. In this example, a high-grade translation was requested. Generally, threshold values will have already been set for existing metrics that follow the procedures described above in the Verifying (or Selecting/Creating) a Metric section. Ideally, stakeholders and organizations have mechanisms and processes in place to continually and empirically evaluate TVs against end product expectations and satisfaction.
The Threshold Value (TV) will determine whether a translation product receives a “pass” rating if the Overall Quality Score (OQS) is equal to or above the TV; similarly, a translation product will receive a “fail” rating if the OQS is below the TV. The TV for the Elections text will be set at 80.
Preparing the Source Text and Target Text for Evaluation
In addition to segmenting and aligning source text segments and target text segments that correspond in content into translation units (TUs), the segments must also be placed in the same sequence of how they appear in the source text and formatted as a file that can be used in the evaluation tool. These types of files are often referred to as a bitext. For some scorecard or CAT-tool programs, that means that the files are in a specific file format.
Additionally, it is important to emphasize that because a bitext orders the segments in the original order of the source text, it differs from a translation memory file in that a translation memory database does not usually keep the original order. Maintaining the original source text order for the TUs is important for the bitext’s use in TQE because it allows evaluators to more easily consider aspects of context, including cohesion, during evaluation.
This stage assumes that the source text and target text are segmented and aligned into segment pairs, often called translation units (TUs). Usually, TUs are segmented and aligned by a CAT tool. Below are the source text and target text for the Elections text, divided into TUs:
Determining the Evaluation Word Count
The final element in Stage 1 is determining the word count for the text that will be evaluated, which is usually generated by a CAT tool. The reader should note that exactly what word count to use is a point of controversy in the translation community; while other TQE models use other variables like the character or line count or the target text word count, MQM TQE uses the source text word count. For more information, please see the Further Reading section at the end of this document.
In MQM TQE, the number of words in the source text is known as the Evaluation Word Count (EWC), which will be used later in Stage 3 for the calculation of Overall Quality Score (OQS). On long term projects, EWC is often established during the quality planning by translation stakeholders and is integrated during this stage.
The Evaluation Word Count (EWC) for the Elections text is 74. Again, although the EWC of the Elections text is much smaller than a sample that most translation stakeholders might choose to evaluate, the shorter text allows for its use as an example in this document.
Error Annotation
The next step in a TQE is to manually annotate the translation units by documenting error instances in a scorecard based on the selected MQM-compliant metric. There are several tools for recording error annotations, including an Excel spreadsheet, an embedded CAT tool feature, and the TRG MQM Scorecard, when a bitext (a list of TUs) is available.
Evaluators should familiarize themselves with the translation specifications and metric for the project and have them on hand during annotation. As evaluators read through the target text checking for correspondence with the source text (according to the translation specifications), each error instance is assigned an error type and severity level from the metric, along with various other pieces of information about the error such as the location of the error in the translation unit and notes about the error. The root cause of the error is optionally included in the note section for each error, where the evaluator should also propose alternate solutions in most cases.
Once the annotation is complete, the tool (be it the TRG MQM Scorecard, Excel sheet, or something else) sometimes displays a list of error instances with other related information. Once the Evaluation Word Count (EWC) has been extracted in Stage 1 or entered in Stage 2, and the error instances have been annotated in some machine-processable format, the rest of the evaluation can be performed automatically.
Evaluators should review the Critical Error Count (CEC), or the number of critical errors in an annotated text. Since critical errors are those that render a text unsable, an evaluation with any number of critical errors greater than 0 would automatically assign a “fail” rating to the translation. Some MQM implementers might end their evaluation process here and send the translation back for retranslation before publication. Others might wait until a quality rating is
assigned to the translation.
Calculating the Absolute Penalty Total (APT)
The crucial initial step toward the Absolute Penalty Total (APT) is calculating an Error Type Penalty Total (ETPT) for each error type. The scorecard is designed to multiply the error count (the number of errors) for each error type times the severity penalty multiplier for a given security level. The intermediate products for each given error type are added up to yield the ETPT for each error.
The list of error types for which an Error Type Penalty Total (ETPT) is calculated can include all the error types in the metric or only those for which there is at least one instance in the annotated list of translation errors.
Using a spreadsheet metaphor, the error counts for each error type are entered in a separate row of a table. Each severity level in any given row is considered separately in its own column. For each severity level, the error count is multiplied by the corresponding penalty multiplier, resulting in the penalty point value for that error type and severity level. A subtotal is calculated by adding up the penalty points for all the severity levels associated with that error type. Then this subtotal is multiplied by the weighting factor for the error type being treated. In the basic example presented here, this can be seen as irrelevant, since the weighting factor is set to 1. If, however, there is a desire to weigh different error types differently, this factor may be varied. The resulting value is the Error Type Penalty Total (ETPT) for that error type (when viewed as a table, for that individual row).
The scorecard is designed to maintain an ongoing sum of all ETPT values, which yields the Absolute Penalty Total (APT). The APT value is then used as the basis for calculating Overall Quality Score (OQS).
Elections Example Calculation of Absolute Penalty Total (APT)
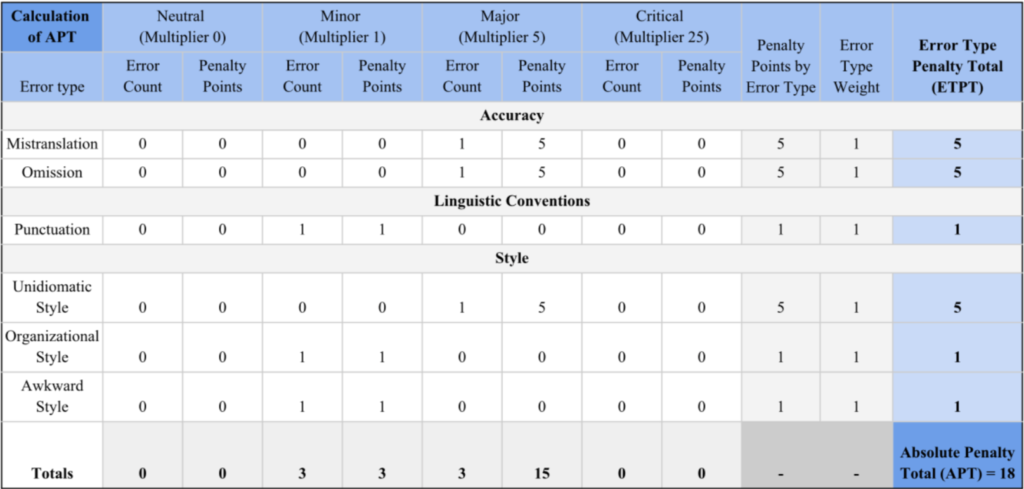
In the annotation of the Elections text included as an illustrative example in this document, there were six errors across six error types. The breakdown of error types by severity level is expressed in Table 1, with the error types listed in the first column: Mistranslation, Omission, Punctuation, Unidiomatic Style, Organizational Style, and Awkward Style.
The error count for a particular error type and severity level is multiplied by the corresponding severity penalty multiplier (this example uses the MQM example 0, 1, 5, and 25) and Error Type Weight (set to 1 for all error types in this example) to yield the Error Type Penalty Total (ETPT) for that error type.
The six ETPTs are then added together to arrive at the Absolute Penalty Total (APT) of 18. This APT value, along with the Evaluation Word Count (EWC), form the basis for calculating the Overall Quality Score (OQS).
The Elections example does not contain any critical errors. If there were a critical error in the Elections text, the text would automatically receive a “fail” rating at this stage, regardless of the APT because the Critical Error Count (CEC) would be greater than 0.
Calculating the Overall Quality Score (OQS)
The next phase of the evaluation process determines a set of so-called “measures” which are then used to calculate the Overall Quality Score (OQS). The OQS is often used to compare quality results between different evaluation projects. Although it is not truly a percentage, it is configured to resemble familiar percentages used to label performance and quality.
The values determined before annotation (Evaluation Word Count, EWC) and during
annotation (Absolute Penalty Total, APT) are manipulated through three additional formulas in order to derive the final Overall Quality Score (OQS). The formulas, listed below, use three specified constraints, which are used to scale the values depending on project specifications or stakeholder expectations. They are set to default values in this document, but they can be adjusted according to stakeholder needs:
- Maximum Score Value (MSV) = 100 (default)
- The Maximum Score Value (MSV) represents a perfect upper score on a scale that is familiar to quality managers and evaluation users. The default MSV 100 has been hardcoded value in the MQM 2.0 scoring model and is a widely accepted industry norm.
- Reference Word Count (RWC) = 1,000 (default)
- The Reference Word Count (RWC) is an arbitrary but convenient word count that can be used to compare all texts of any length by calculating the number of penalty points per 1000 words regardless of the length of evaluation texts in question. Although useful when comparing texts of different lengths, RWC has no effect on the final value of the Overall Quality Score (OQS).
- Scaling Parameter (SP) = 1 (default)
- In this example, the Scaling Parameter (SP) has the default value of one. The value of SP can be set to slightly more or less than one, typically from 0.5 to 2.5, but a discussion of how to decide on a value for SP other than one is beyond the scope of this Introduction.
As indicated, the Evaluation Word Count (EWC) and Absolute Penalty Total (APT) are manipulated together with these three constraints in order to calculate the following values.
- Per-Word Penalty Total (PWPT)
- The PWPT is determined by dividing the Absolute Penalty Total (APT) by the actual Evaluation Word Count (EWC). This value is usually generated by the CAT tool that produced the original bitext and will probably be different for each evaluation project. The PWPT is almost certainly a fractional value that enables comparison of evaluation results from projects of varying length. It is not, however, an easily conceptualized value for the average user. For this reason, a series of operations are performed in order to express the value in a more familiar form that resembles a percentage value.
- The formula for PWPT (Per-Word Penalty Total) is PWPT = APT / EWC. For the Elections example, the formula would be: PWPT = 18/74 = 0.243.
- Overall Normed Penalty Total (ONPT)
- The next step involves calculating the Overall Normed Penalty Total (ONPT). Multiplying the Per-Word Penalty Total (PWPT) by the Reference Word Count (RWC), whose default value is 1000, but can be modified) expresses a per thousand error penalty total, which provides a convenient standard of comparison between different evaluation projects. It is also multiplied by the Scaling Parameter (SP), which has a value of 1 in this example.
- The formula for the ONPT (Overall Normed Penalty Total) is ONPT = PWPT × RWC x SP. For the Elections example, the formula would be: ONPT = 0.140 x 1000 x 1 = 243.
- Overall Quality Fraction (OQF)
- In order to shift the score into the range of the Maximum Score Value (MSV, 100 in this example), the next step involves calculating the Overall Quality Fraction (OQF) by first dividing the Overall Normed Penalty Total (ONPT) by the Reference Word Count (RWC). This value is then subtracted from 1. The concept here is that if the ONPT represents error penalties, the remainder of this operation will represent that portion of the evaluation translation that is correct. Note: The INTEGER “1” in the OQF formula is the actual number “1” and does not vary with evaluation projects. It is not related to the SP (which in this example also happens to have a value of “1”).
- The formula for the OQF (Overall Quality Fraction) is OQF = 1 – (ONPT / RWC). For the Elections example, the formula would be: OQF = 1 – (140 / 1000) = .757.
Alternative Method of Calculating OQF
Alternatively, the calculation of Overall Quality Fraction (OQF) can usually be simplified by subtracting the quotient of the Absolute Penalty Total (APT) divided by the Evaluation Word Count (EWC). Doing so effectively skips the intermediary stages that produce the Per-Word Penalty Total (PWPT) and Overall Normed Penalty Total (ONPT). If the Scaling Parameter (SP) is 1, this can be done since PWPT and ONPT are fractional values manipulated by the constraints to move the quotient of the EWC and APT to different ranges that are better suited for different levels of analysis. Either way, the result of OQF is the same value.
Therefore, if an evaluator only wants to obtain the Overall Quality Fraction (OQF), later used to arrive at the Overall Quality Score (OQS), they can use the formula OQF = 1 – (APT / EWC). For the Elections example, this simplified formula would be OQF = 1 – (18/74) = .757. Note that this results in the same OQF.Summary of Overall Quality Score (OQS).
- Overall Quality Score (OQS)
- The final calculation of the Overall Quality Score (OQS) is then resolved to a percentage-like value by multiplying the Overall Quality Fraction (OQF) times the Maximum Score Value (MSV), represented by the formula OQS = OQF × MSV.
- For the Elections example, the formula would be: OQS = 0.757 x 100 = 75.7.
This section of the document provides the same concrete example but this time with a detailed description of the formulas used in translation quality evaluation. Again, the method for assigning penalty points and calculating OQS used in this Introduction is only one of many methods used by MQM implementers. It should be remembered, however, that all MQM-based methods of TQE share three things in common: deciding how much text will be evaluated (Evaluation Word Count, EWC), assigning penalty points (Absolute Penalty Total, APT), and calculating an Overall Quality Score (OQS). In addition to providing formulas, this section describes the severity levels used in the example and adds other details about evaluation.
When Does the Evaluation Take Place?
Summary of Overall Quality Score (OQS)
The formulas used to calculate the Overall Quality Score (OQS) are based on just two variables, Absolute Penalty Total (APT) and Evaluation Word Count (EWC). By inputting these two values into the sequence of formulas, OQS can be calculated automatically with a spreadsheet or program or manually with a four-function calculator; in either case, they should yield the same OQS value.
To review the process up until this stage with the calculations, the following formulas use two variable values, Absolute Penalty Total (APT) and Evaluation Word Count (EWC), from the Elections data and the constraint values. It should be remembered that the constraint values included in this document are the default values assigned to the constraints, but they can be changed by users if desired.
- Variables
- Evaluation Word Count (EWC): 74 (determined before annotation)
- Absolute Penalty Total (APT): 18 (calculated during annotation)
- Constraints (default values explained above)
- Maximum Score Value (MSV): 100
- Reference Word Count (RWC): 1,000
- Scaling Parameter (SP): 1
| Per-Word Penalty Total = APT / EWC | PWPT = 18 / 74 | =0.243 |
| Overall Normed Penalty Total = PWPT × SP × RWC | ONPT = 0.243 x 1 x 1,000 | =243 |
| Overall Quality Fraction = 1 – (ONPT / RWC) | OQF = 1 – (243 / 1,000) | =0.757 |
| *Simplified OQF formula: OQF = 1 – (APT / EWC) | OQF = 1 – (18 / 74) | =0.757 |
| Overall Quality Score: OQF × MSV | OQS = 0.757 x 100 | =75.7 |
Quality Rating
A Quality Rating is determined based on the Overall Quality Score (OQS) calculated in the previous section. Quality evaluation stakeholders can define one or more quality ratings based on the quality measures and, as appropriate, other aspects of a translation product, translation project, or quality evaluation project. They can provide ways to apply the quality measures to the particular quality needs and quality metrics of the quality evaluation stakeholders in order to implement continuous improvement in the translation production process.
One common quality rating is the pass/fail rating. A pass/fail rating assigns a label of “pass” or “fail” to a translation product based on two factors—the number of critical errors (Critical Error Count, CEC) and the value of one of the Overall Quality Score (OQS). To pass, a translation product must, first, have no critical errors. Again, any critical error in the translation product will typically render the text unusable, and therefore is automatically labeled with a “fail” rating. Second, the translation product must achieve an OQS greater than or equal to the established Threshold Value (TV) for a given project.
Assigning a Quality Rating to the Elections Text
The Elections text would receive a “fail” rating since the Overall Quality Score (OQS) of 75.7 is below the Threshold Value (TV) of 80.
Possible follow-up actions are described in the previous section, the one without formulas.